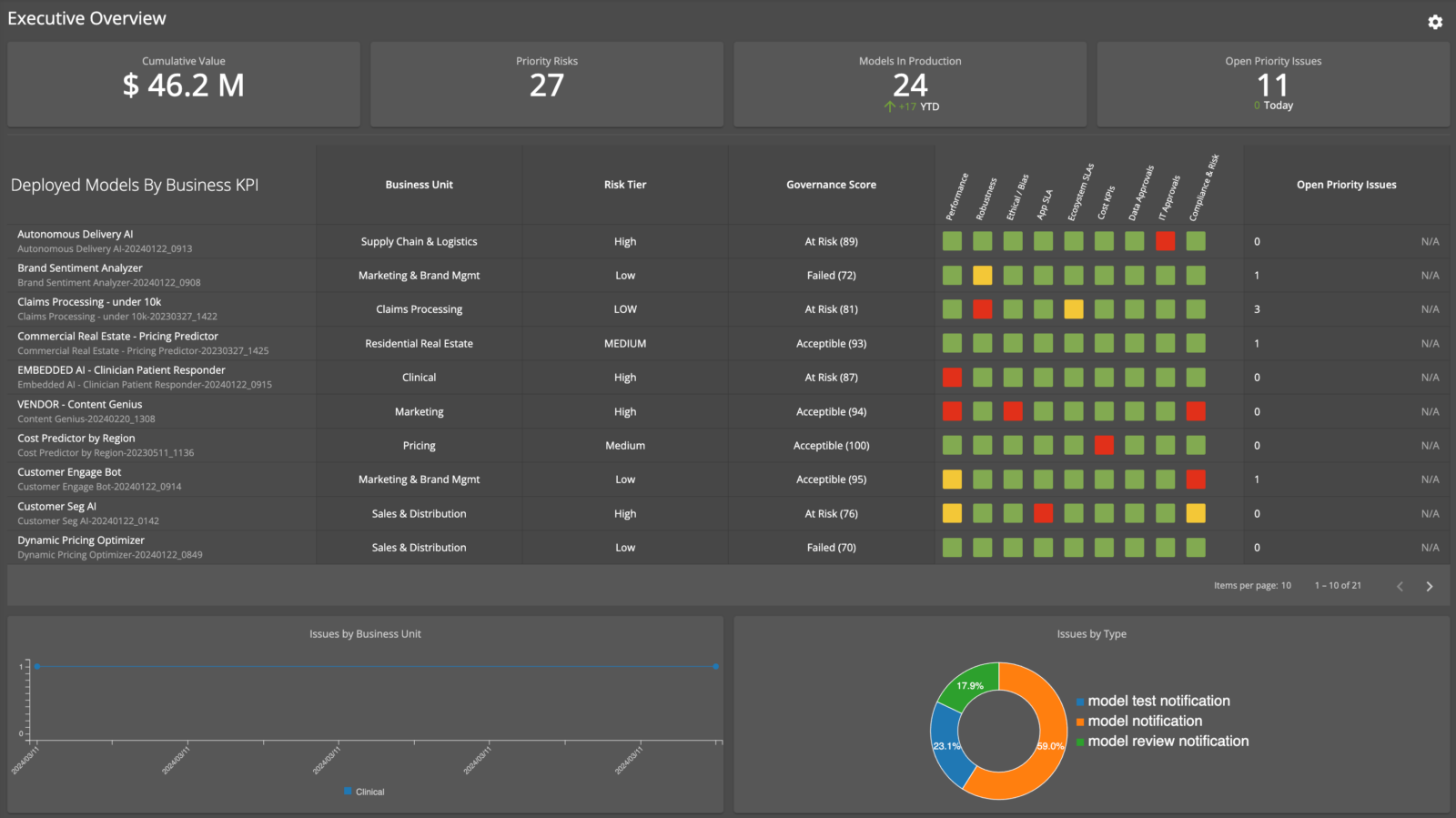
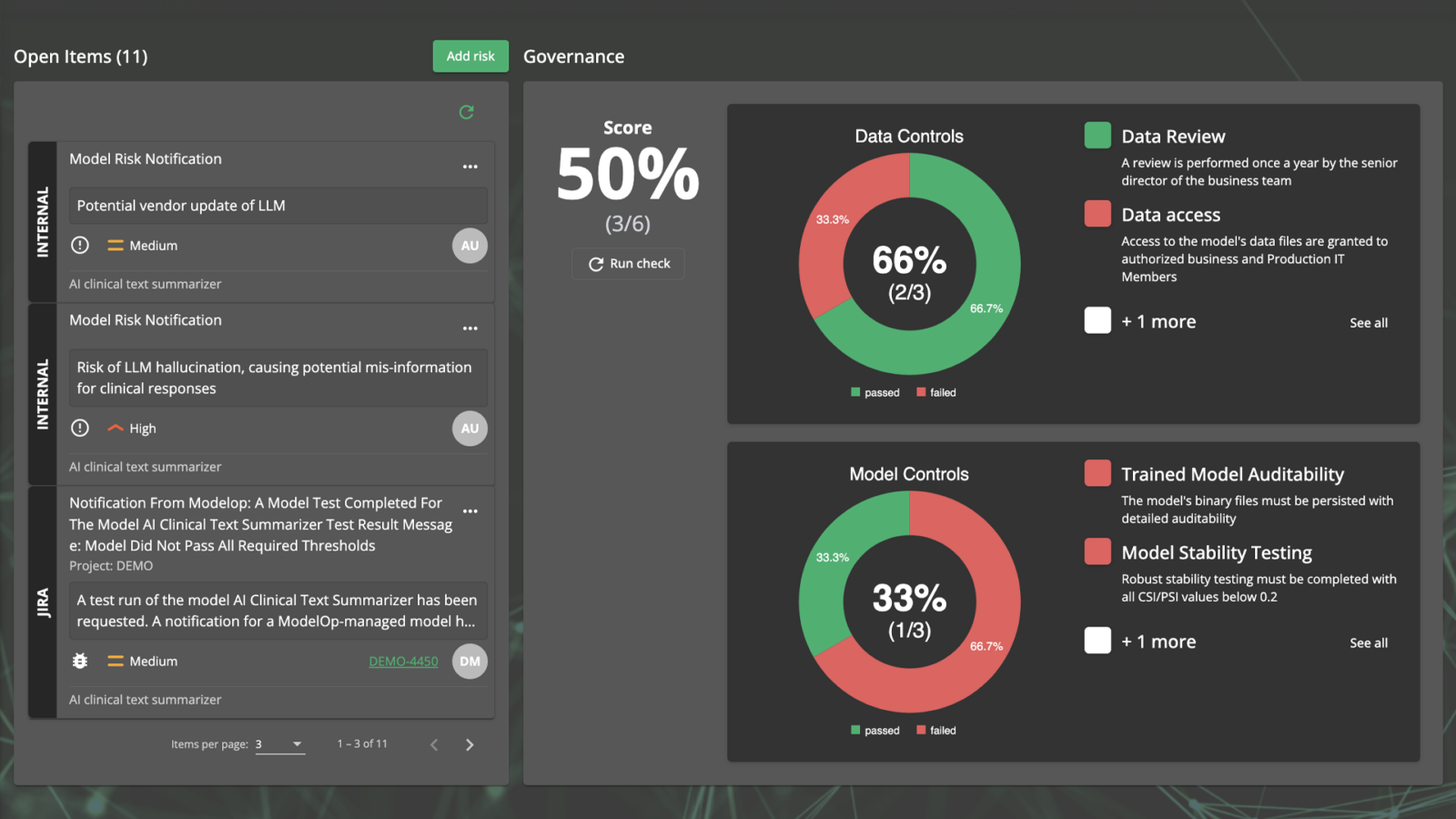
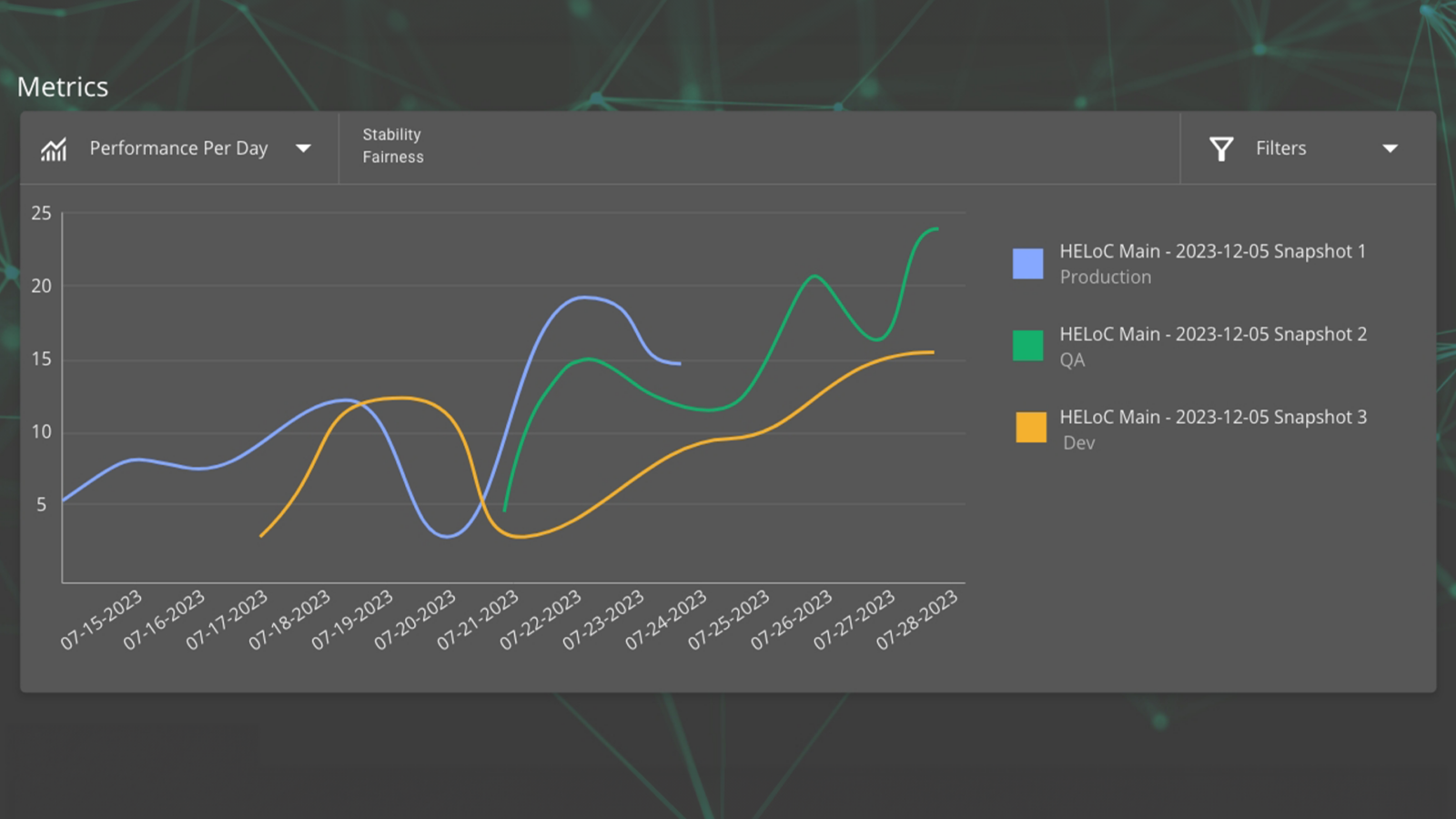
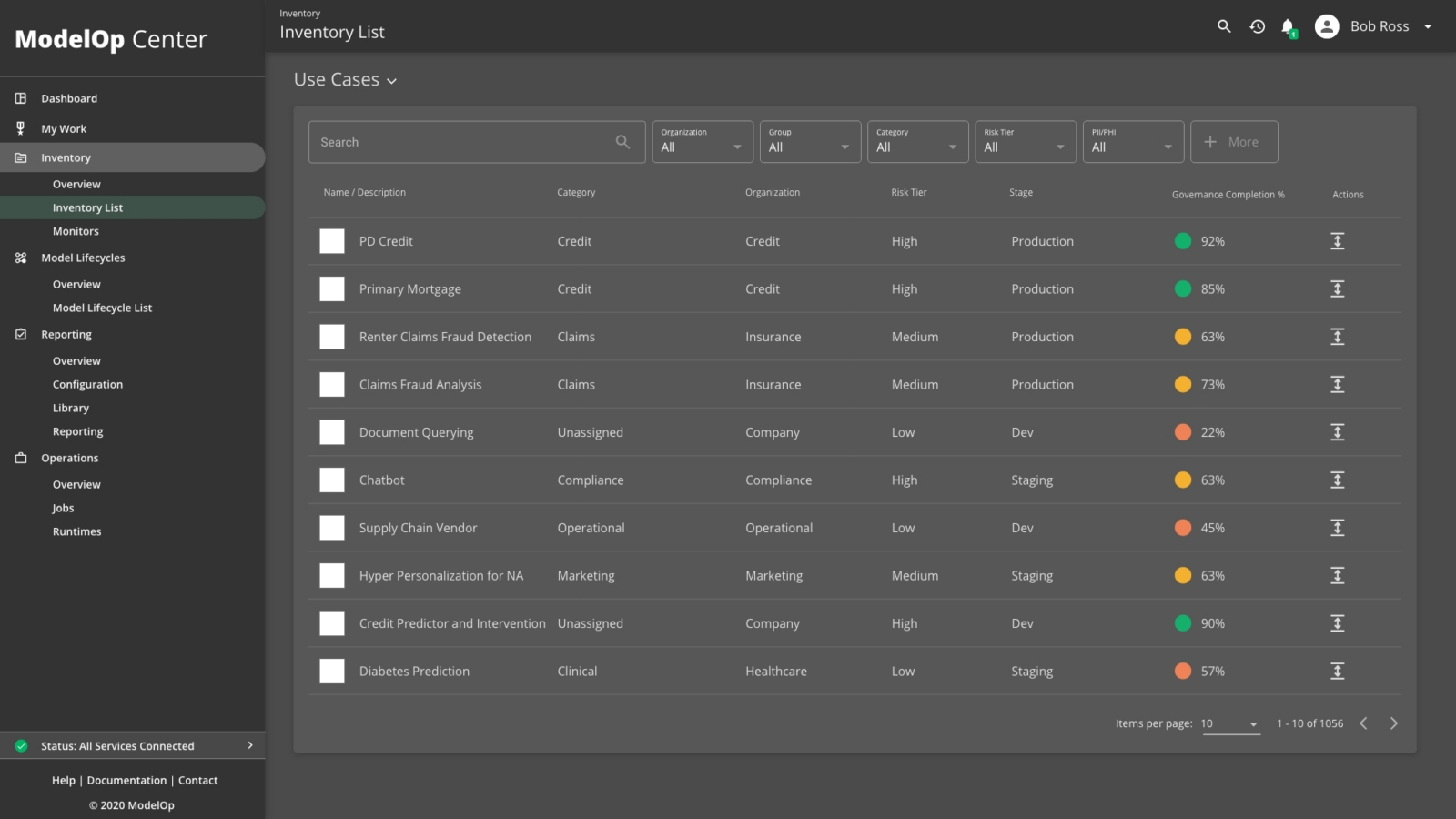
Who’s Accountable for AI and its Risks? Why Enterprise CEOs Need to Assign AI Ownership Now
Webinar | Tuesday, April 30th | 1pm ET
Webinar | Tuesday, April 30th | 1pm ET
Menu
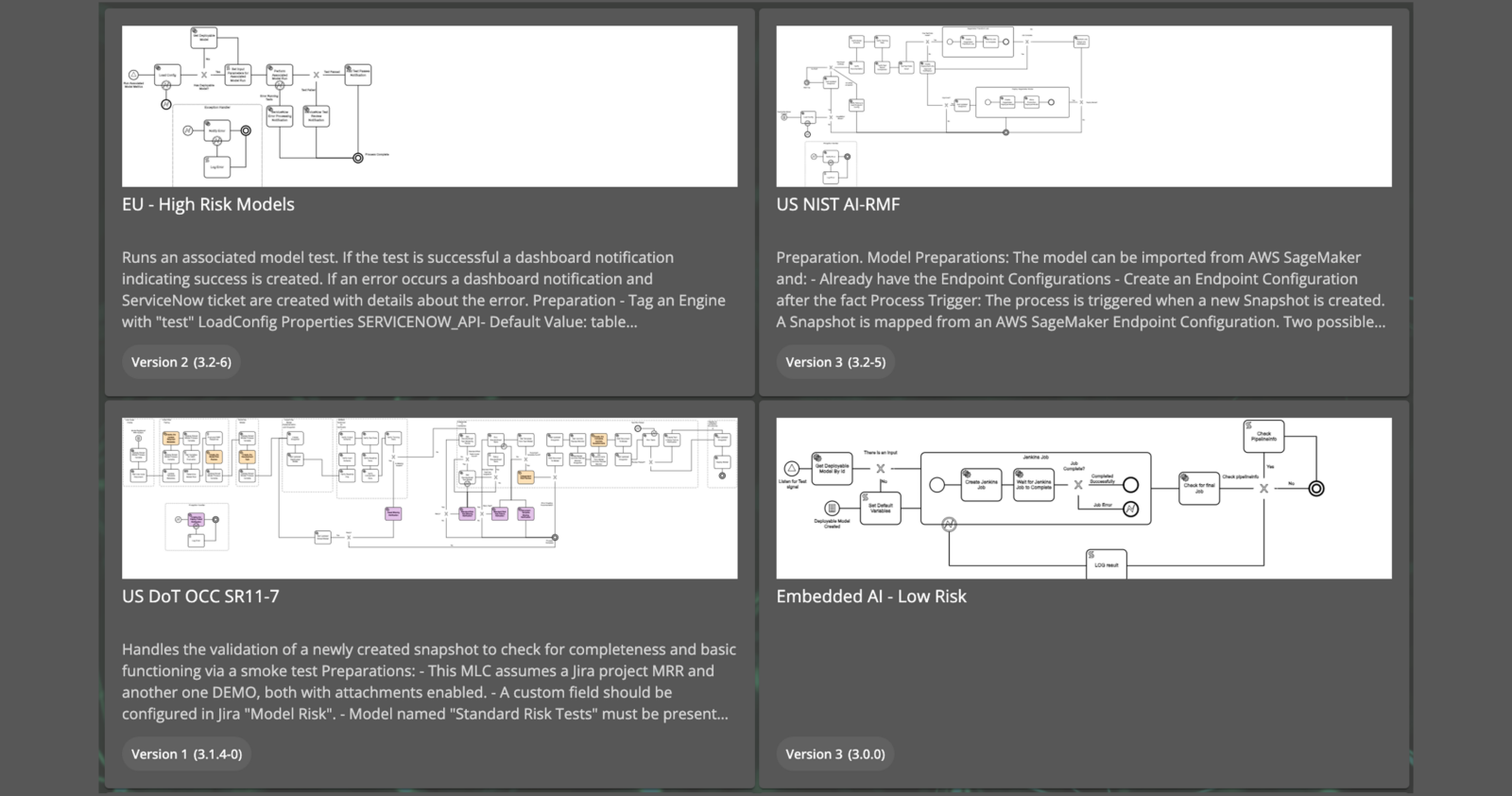
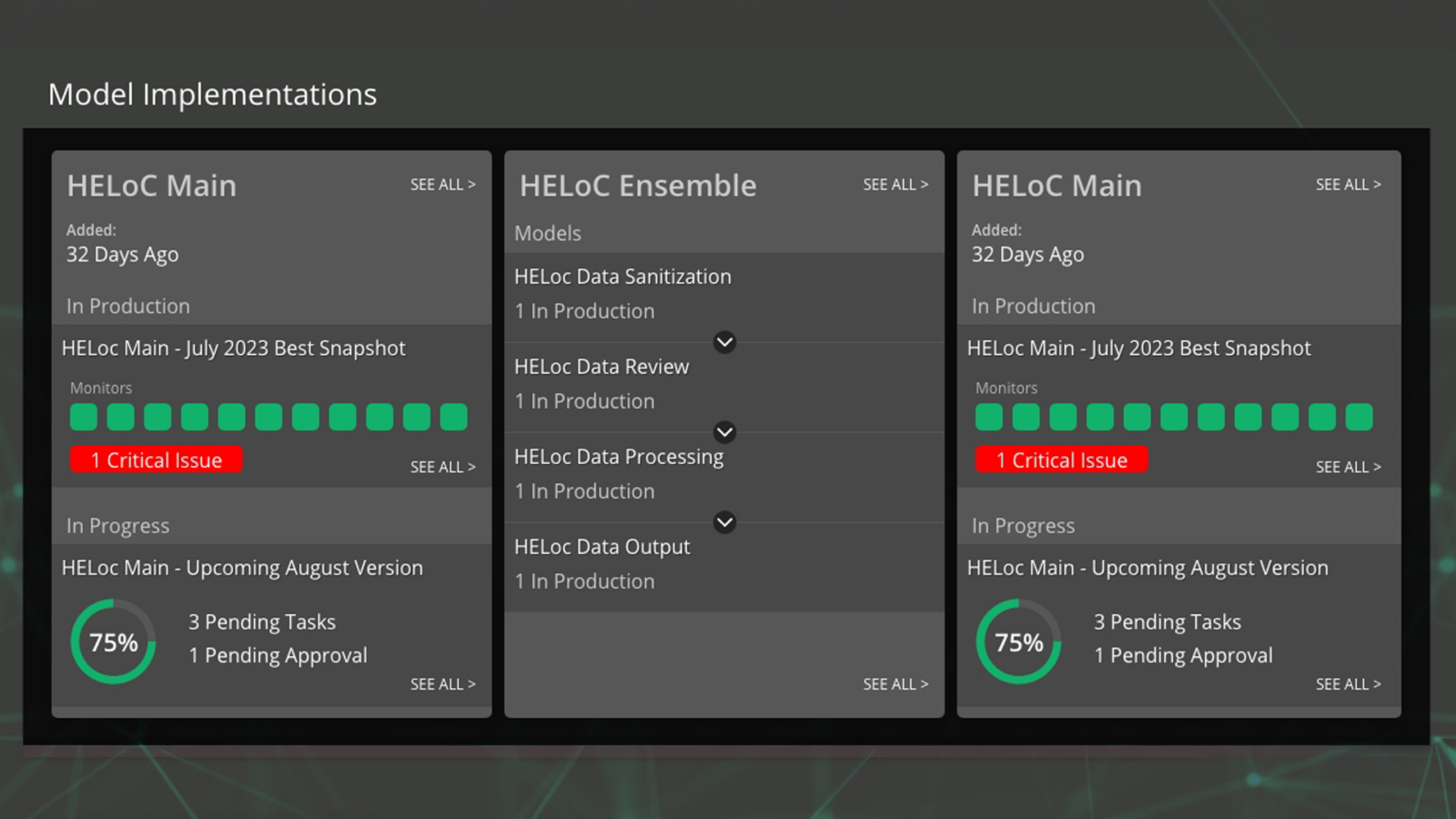
- ProductSEE. GOVERN. SCALE.See how every AI investment is performingImplement governance without stifling innovationStandardize operations and scaleModelOp Center FoundationPowering EV, MRI, and AIOThe source of truth for everything about every model across the enterpriseAutomated Process WorkflowsData at your fingertipsUnlock the value of your AI investmentState of ModelOps 2022
The State of ModelOps report offers compelling insights into emerging challenges, trends, and strategies. - Solutions
- Resources2022 ModelOps Summit
Join senior peers, colleagues and industry leaders to discuss the challenges, innovations and opportunities in ModelOpsRegister Now ⟶BBSI achieves near real-time credit scoring updates with ModelOpRead More ⟶Read More ⟶ - Company